
Context and motivation
Covid-19 outbreak has had an immense impact on daily lives of most people in the world, this has altered many different areas of life such as travel, sport, career, education, health and many more areas. In particular, the media and reporting has had a significant coverage relating to Covid-19. The newspapers usually indicate how society reflect on Covid-19 and by analysing the newspaper over time, you can see how topics relating to Covid-19 change. Please see our two previous blog posts on topic modelling (https://emergentalliance.org/?p=1638) and sentiment analysis of newspapers (https://emergentalliance.org/?p=1638).
Government restrictions and lockdown measures have concrete impact on businesses and everyday life, and we believe articles around this topic are of special interest for many businesses and decision-makers. However, they are difficult to be manually detected among overwhelming amount of Covid-19 related articles being published every day.
The purpose of this analysis is to provide the government and businesses a method to automatically “scan” the articles and detect the ones related to Covid-19 and specifically around the government and lockdown measures. Specifically, we would like to address the following questions:
- Can we identify which topics are related to Covid-19?
- Can we classify which of these Covid-19 articles are related to government measures?
The following analysis is the results of topic modelling and text classification using Natural Language Processing (NLP) methods on news articles from UK newspapers related to Covid-19.
Code Available on Github
Our Method
Topic modelling
One of the prerequisites of building any classification pipeline is the availability of data that is labelled properly. Here we use LDA (latent Dirichlet allocation) that is a method of topic modelling to find the most important topics relating to Covid-19. LDA clusters the corpus into a set of topics by taking the assumption that the corpus of articles is essentially a distribution of topics, which can then be in turn looked at as a distribution of words. We used Gensim library to discover topics and pyLDAviz to visualize them.
Then we label articles to their corresponding topic and build a binary label for the topic that relates to government and lockdown measures.
To ensure the result of topic modelling is a set of well-separated clusters, we evaluate the results through the Coherence Score. This metric identifies the optimal number of topics in the LDA and measures how semantically similar the most important words within a topic are.
Classification
After labelling the articles using topic modelling, we build a classification pipeline in Python using Sklearn library to predict whether the article is in relation to Covid-19 lockdown or another aspect of Covid-19. The trained model was a Linear Support Vector Machine (SVM) using Stochastic Gradient Descent. The parameters were optimized by hyperparameter tuning using Grid Search.
We also used AutoAI for building the classification pipeline and compared the results. AutoAI is an IBM technology available on Cloud Pak for Data environment which performs supervised learning. AutoAI finds the optimal model, by benchmarking of different algorithms, with hyperparameter optimization, as well as feature engineering being performed.
The figure below shows the entire NLP classification workflow and tools used in this work. In the NLP workflow, from left to right, first, we ingest data obtained from Socialgist containing UK News Articles, then we apply a set of pre-processing techniques to normalize text and remove noise in data.
The result is a clean dataset ready for topic modelling and training the classification model. Finally, we evaluate the model performance through different metrics.
NLP classification workflow
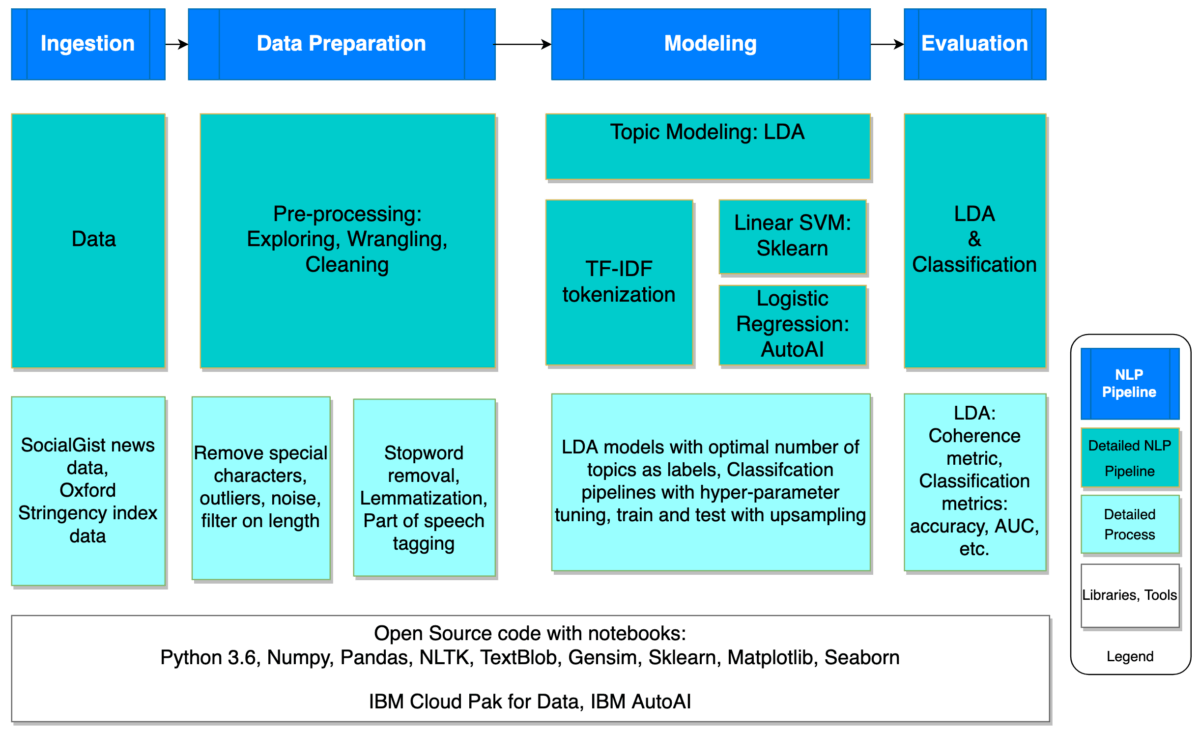
For this analysis, we focused on two UK-based news providers that target the general public and cover a variety of topics, from 1st of January till the end of May 2020: Metro.co.uk and the sun.
Can we identify which topics are related to Covid-19?
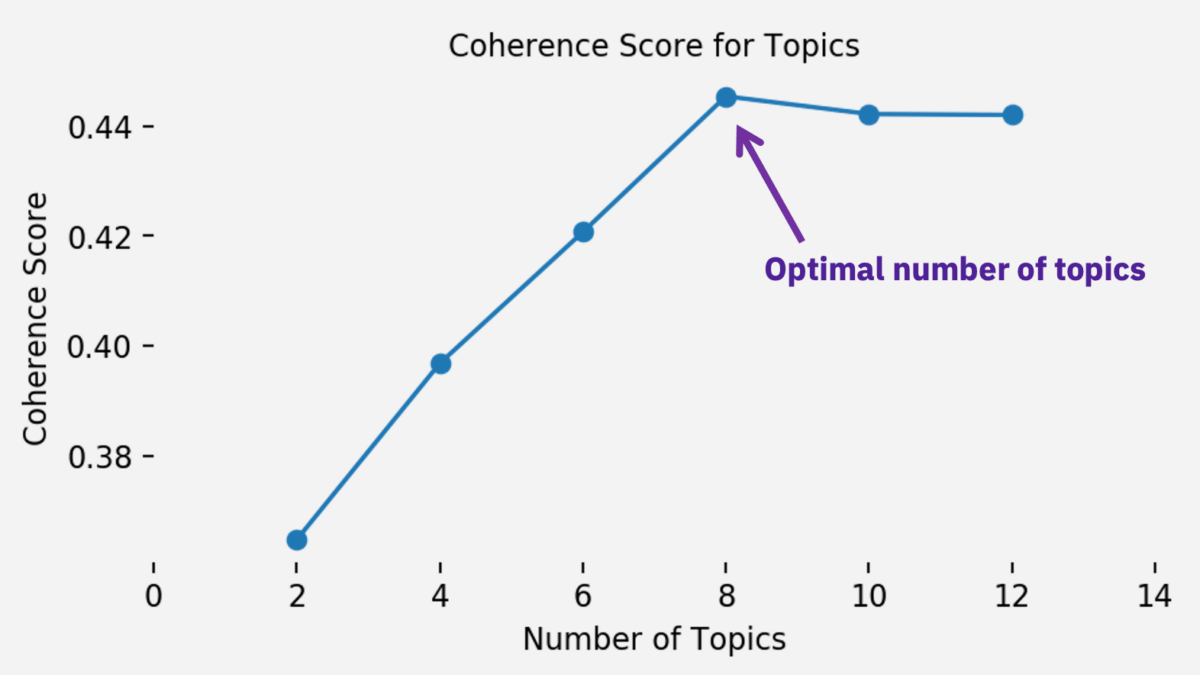
By applying LDA and Coherence Score, we succeeded to discover 8 well-separated clusters. In the figure below, we can see the coherence scores for a range of topics, which the highest score indicates the optimal number of topics. It is essential to obtain the optimal number since the better separated the clusters are, the labelling would be more accurate and as a result, the classification pipeline would classify articles with higher accuracy as well.
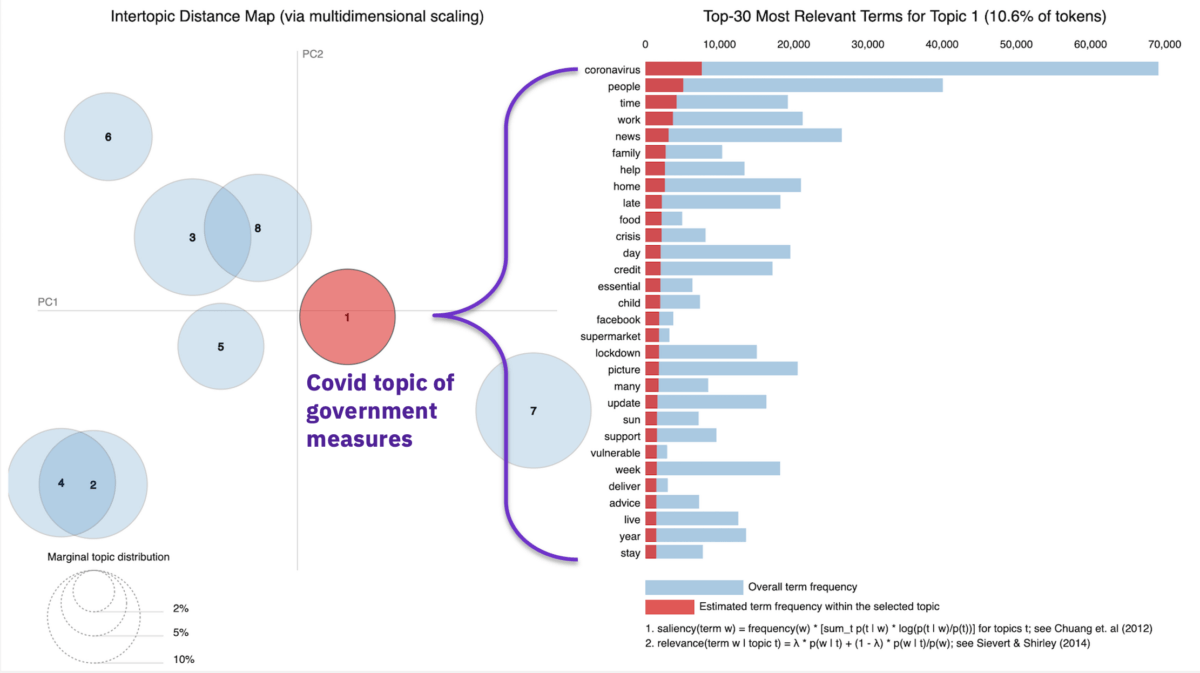
The picture below shows the plot of topics. On the left, the clusters are shown which their size indicates the marginal topic distribution. On the right, the most important words of a topic are shown with their frequency measure within that topic (red bars) versus their overall frequency in the entire corpus (blue bars). Here we can see that topic-1 is the topic that relates to government and lockdown measures as it includes relevant words like ‘coronavirus’, ‘lockdown’, ‘government’, etc.
Once the topics are found from LDA, then we use this data as labels to classify and assess if a news article is a Covid-19 lockdown related or not. A binary classification method is used to address the second question.
Can we classify which of these Covid-19 articles are related to government measures?
The classification pipeline with a Python library of Sklearn includes two steps: first we converted the corpus of articles to a matrix of tf-idf features using Sklearn TfidfVectorizer. Then we trained a regularized Linear SVM model with Stochastic Gradient Descent. The pipeline parameters were optimized using Grid Search.
We also trained a classification model through AutoAI with the tf-idf matrix. Logistic Regression was found as the best performing model based on the AUC metric. The picture below shows the end to end process in AutoAI where four pipelines are generated. The pipelines are iteratively improved through feature engineering and/or hyperparameter optimization.
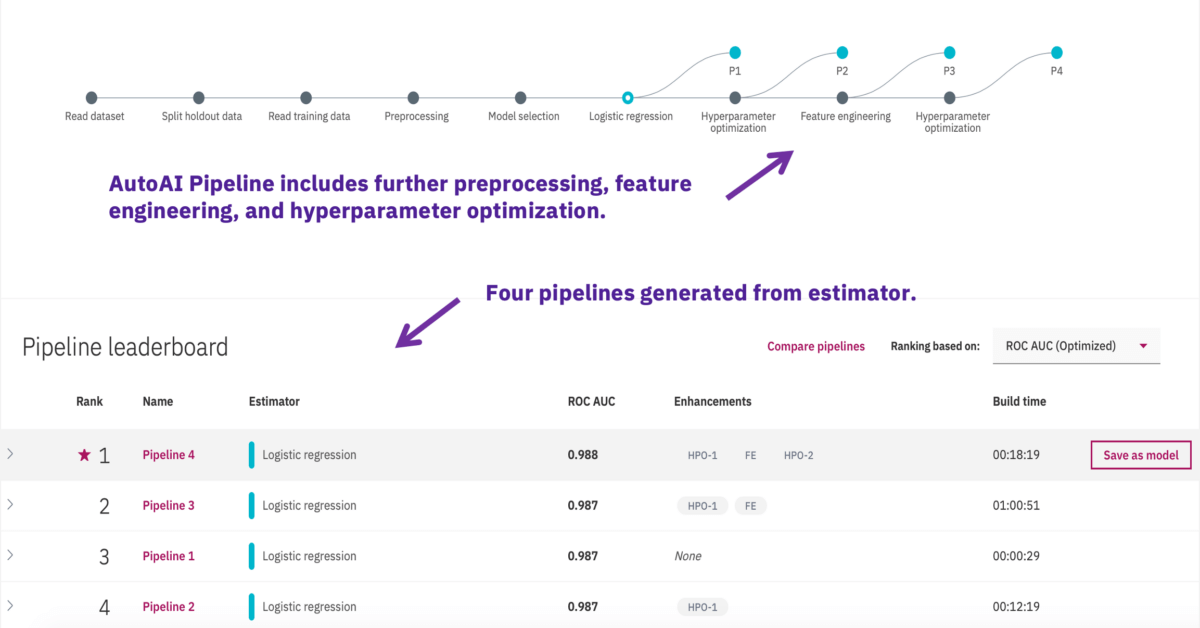
Feature engineering transforms the raw data into the combination of features that best represents the problem to achieve the most accurate prediction. Here AutoAI has used Principle Component Analysis (PCA) for dimensionality reduction and feature transformation.
The chart below shows the feature importance. In addition to new generated features, the most important features (words in the tf-idf matrix) of the classification model are shown. We can see distinctive words relating to the government restrictions and lockdown are more important in the classification such as ‘measure’, ‘lockdown’, and ‘reopen’.
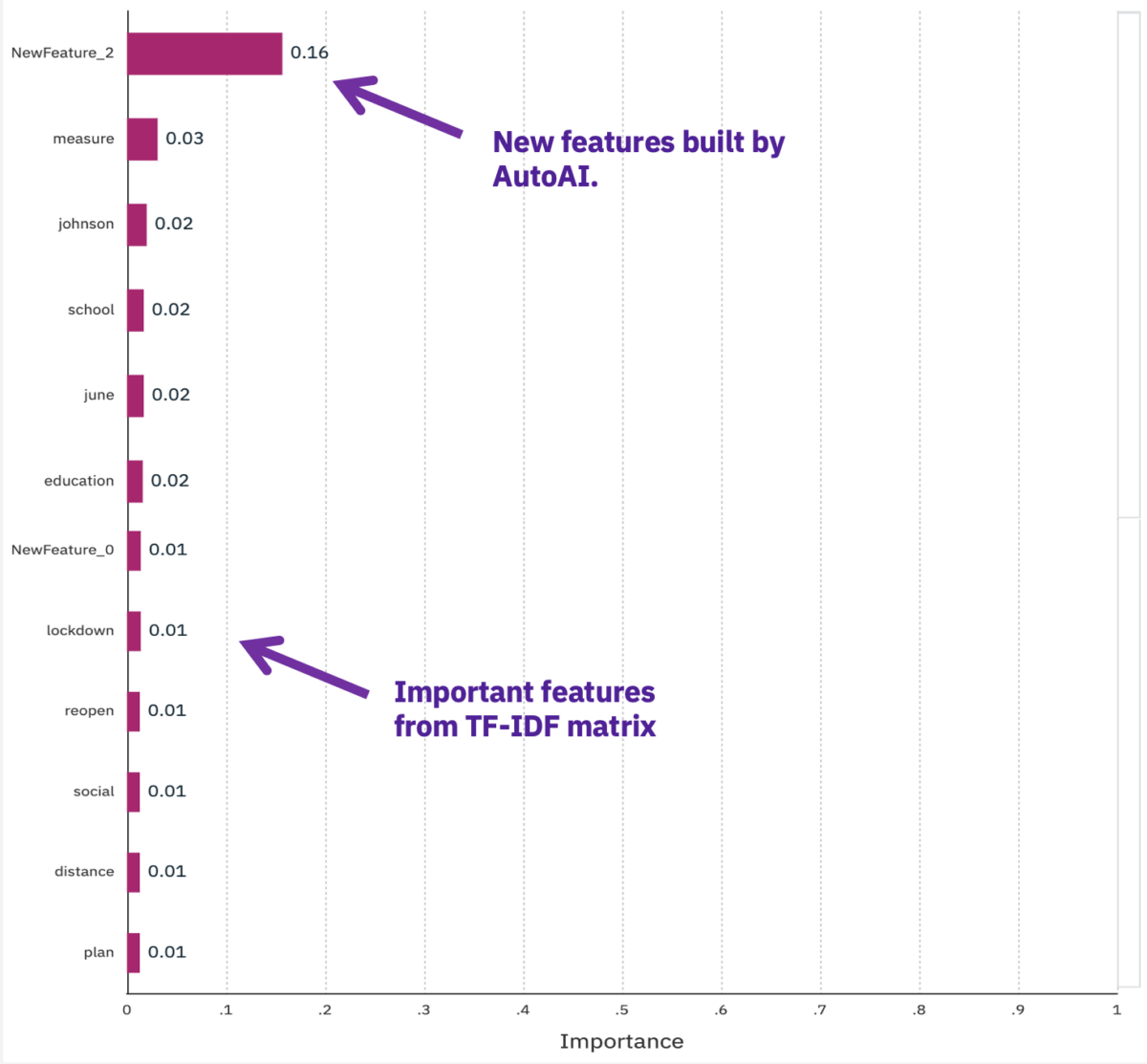
We report the results of the classification model on the following evaluation metrics:
- Accuracy: the number of correctly predicted points out of all the points.
- AUC (Area Under ROC Curve): an aggregate measure of performance across all possible classification thresholds.
- Precision: the fraction of correctly predicted lockdown related articles out of all predicted lockdown related articles.
- Recall: the fraction of correctly predicted lockdown related articles out of all actual lockdown articles.
- F1 Score: an overall measure of a model’s accuracy that combines precision and recall.
The figure below shows the result of AutoAI and Sklearn pipeline side by side. As a comparison, Logistic Regression results in significantly higher AUC and Recall while Linear SVM has much higher Precision.
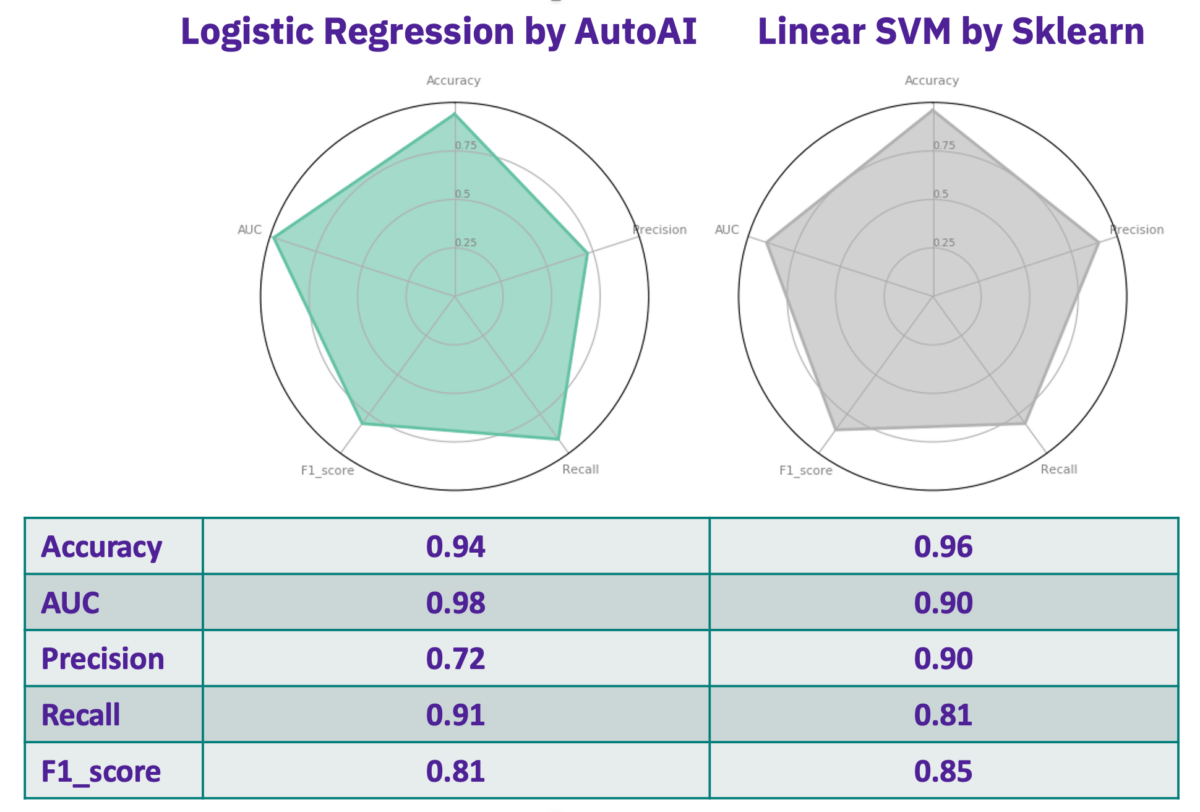
Selecting the best model would depend on the wish of the potential user to receive articles with either having a low false-positive rate (higher Precision) or having a low false-negative rate (higher Recall). In simple terms, if the user is interested to receive articles that are exclusive to Covid-19 government and lockdown measures with as few articles as possible from other Covid-19 related topics, the Linear SVM with higher Precision might be a better fit. However, if the user prefers to get as many articles as possible on Covid-19 government and lockdown measures even with a higher number of irrelevant articles, the Logistic Regression with higher Recall might be the preferred model.
Code Available on Github
Main Takeaway
In this analysis, we explained that we can cluster a corpus of news articles into well-separated topics and identify what topics are related to Covid-19, through using LDA and the coherence score. Also, we successfully classified whether the news article is related to Covid-19 government restrictions and lockdown measures through using Linear SVM, then we showed that AutoAI facilitates this process by rapid benchmarking of different algorithms and optimizing the performance, as well as providing explainability of the results.
Disclaimer: This information can be used for educational and research use. Please note that this analysis is made on a subset of news content. The authors do not recommend generalizing the results and draw conclusions for decision-making on these sources only.
Authors:
- Anthony Ayanwale is Data Scientist with Cloud Pak Acceleration team where he specializes in Data Science, Analytics platforms, and Machine Learning solutions.
- Mehrnoosh Vahdat is Data Scientist with IBM Data Science & AI Elite team where she specializes in Data Science, Analytics platforms, and Machine Learning solutions.
Special thanks to Klaus Paul, Erika Agostinelli, Vincent Nelis, Alexander Lang, and Mara Pometti who helped and inspired us in this work.
We are a team of data scientists from IBM’s Data Science & AI Elite Team, IBM’s Cloud Pak Acceleration Team, and Rolls-Royce’s R2 Data Labs working on Regional Risk-Pulse Index: forecasting and simulation within Emergent Alliance. Have a look at our challenge statement!