
One machine learning method to predict whether a hospital system will reach its capacity in the fight against COVID-19
By Rachael Dottle and Mara Pometti
In terms of COVID-19 and the pandemic, our understanding of the spread of the disease is unclear. Because of this we, as part of IBM, joined the Emergent Alliance with the aim to provide meaningful insights for governments, health care leaders, corporations and citizens to better inform their decisions through AI. We model the predicted spread of disease, strain on health systems, and the need for certain things like face masks or ICU beds to better provide estimates that decision-makers use to allocate resources and protect people.
One of the first work streams we focused on was to track and predict the infection dynamics of COVID-19. The team of data scientists Marius Vileiniskis, Sarah Boufelja-Yacoubi and Kwuyha Lee (part of IBM Data Science Elite), began to develop a predictive approach to modeling the demand for health care resources like ICU beds. The goal was to quickly develop a model to predict the number of hospital beds needed in the next few days, based on data collected on incoming patients and the spread of the disease. “We started off with … [predicting] the variable describing how many patients are in the hospital at a given moment and the only information that shows what is the workload for hospitals. One side effect of using this variable is that it’s bounded by the capacity of the hospital, e.g. you can’t admit more patients than you have the resources to look after them,” says Marius.
Being able to predict how many ICU and hospital beds are needed in a given place is valuable and essential because it allows hospitals to plan for expected patients, and it allows suppliers and local governments to manage the need for supplies.
Critically, if the expected patient flow is over the limit of a hospital’s capacity, interventions can also be made in anticipation of a crisis like a hospital having no beds left for patients in need.
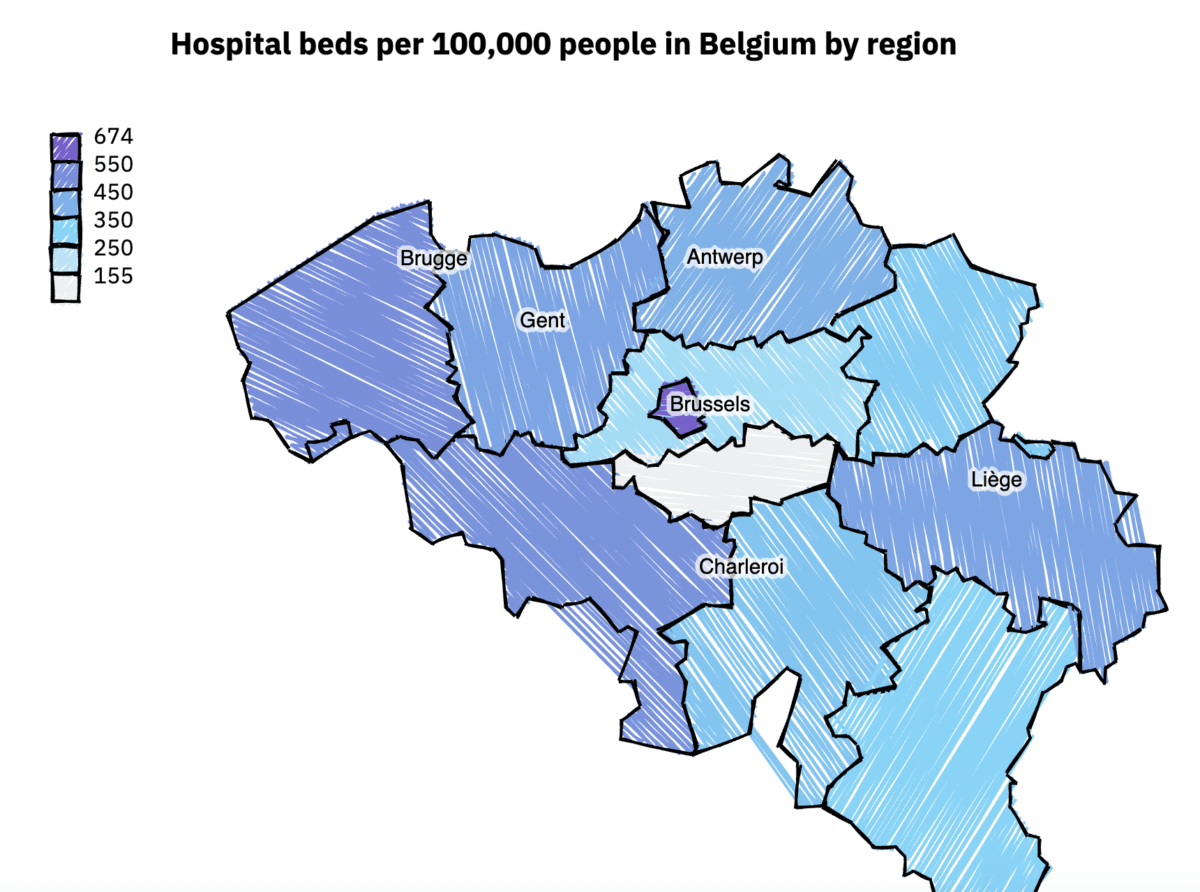
In Belgium, for example, the hospital capacity for each province ranges from about 155 beds per 100,000 people in Walloon Brabant to 674 per 100,000 in Brussels, the capital. That’s about 8,000 beds total in Brussels, and 630 in Walloon Brabant.
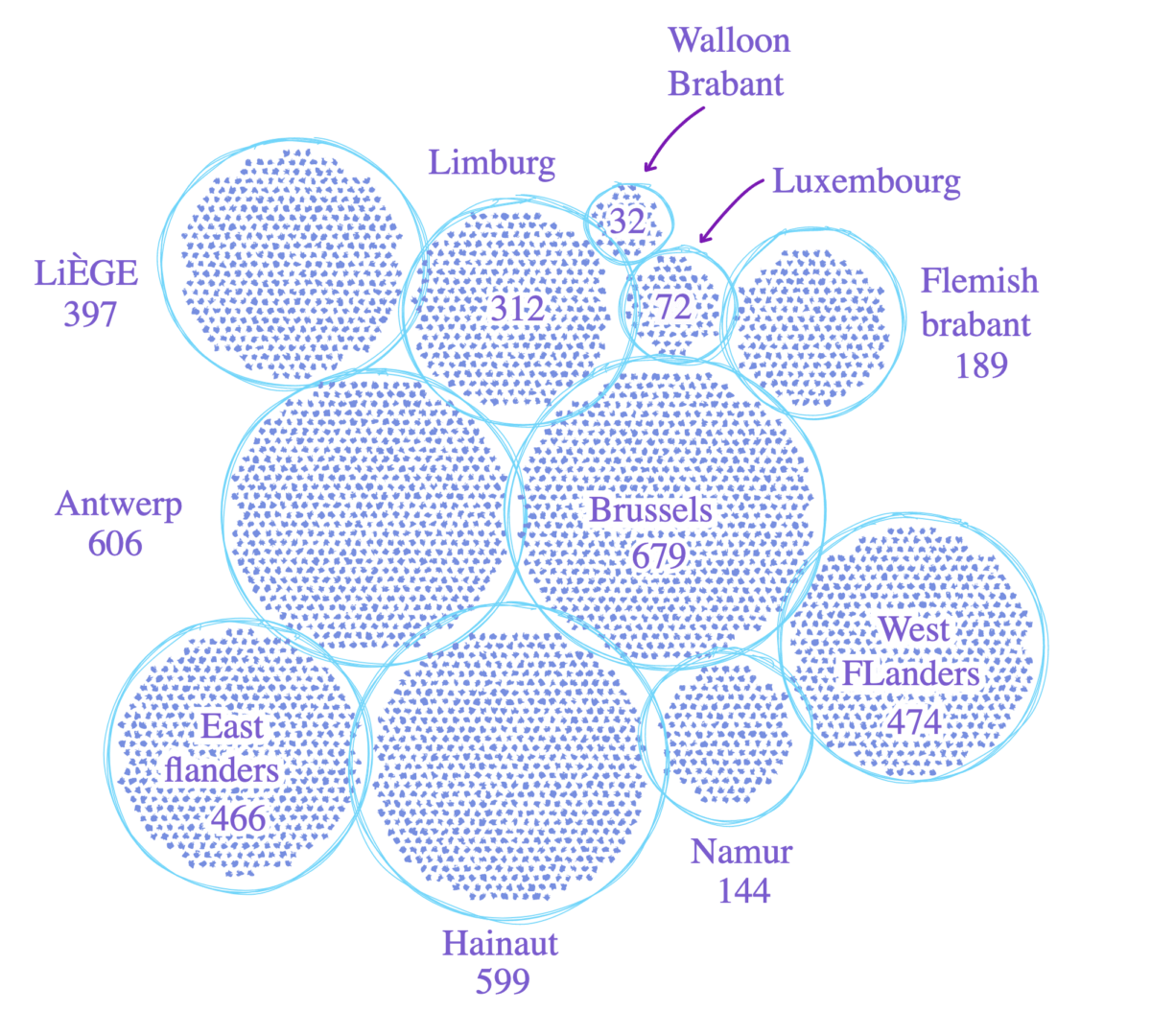
To build a model to accurately predict the demand for hospital beds, the team needed to start with baseline data like the population, hospital capacity, and infection rates and the past weeks of COVID-19 spread. As Kyuhwa puts it, “what’s important is how reliable and realistic our prior knowledge is: if we have accurate prior knowledge, then the model will perform well, otherwise not.”
Because Belgium has some of the most complete data, our data scientists started there. Every country has approached tracking and collecting information on COVID-19 differently; Belgium stands out because it has data on both the number of cases and tests, and the number of beds and resources in its hospitals.
The team decided to build three models, two which predict short-term for the next few days, and one which predicts at a higher, country-wide level. The prediction results vary slightly, based on the models used and the assumptions made. Multiple models give a more varied picture of the problem: relying on one model can lead to misunderstanding or poor planning. “It’s always a good practice to look at different models and choose the best, or combine them, ideally, one model will compensate for the weaknesses of others,” Sarah notes.
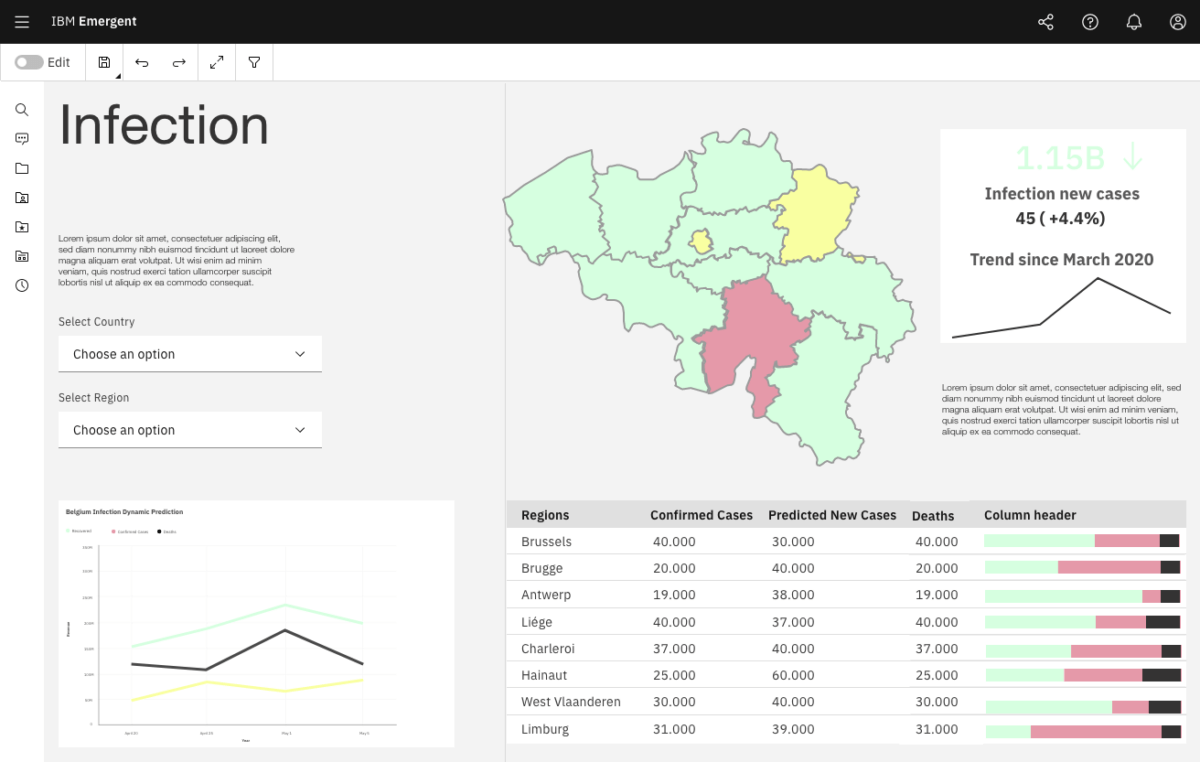
The result is predictions of new and incoming patients by day. These results inspired the team to design a concept of how to visualize and display the predicted outcomes.
About the Authors:
Mara Pometti is a Data Strategist with IBM Cloud & Cognitive Software CDO team where she specialises in data design and has a background in journalism.
At the beginning of the Covid-19 emergency, Mara took the lead in envisioning a platform called Krino where to publish stories with compelling data visualizations to drive people’s attention to the AI outcomes produced by the data scientists in the Data Science & AI Elite Team and to use for the good of society the the data collected in the IBM Covid-19 Trusted Data Fabric. The main objective of Krino is to use storytelling to unlock the science and the math behind those models and to translate their outcomes into meaningful narratives that relate to people who want to understand AI, but don’t have the technical skills to understand it. The vision behind Krino is to provide a framework to help people better see through AI in order to obtain a clearer understanding of how the changes caused by Covid-19 that hit cities, services and job market might impact their habits and behaviors. Read more about the Krino vision on the Data Science & AI Elite website.
Rachael Dottle is a graphics journalist who over her time in IBM Data Science & AI Elite Team specialised in data design and information design. Rachael played a major role in the development of the Krino project above mentioned. She worked at the project as data journalist and her role was fundamental in the realization of the ultimate prototype.
Data Scientists:
Marius Vilieniskis, Senior Data Scientist – Machine Learning Engineer IBM Cloud and Cognitive Software
Sarah Boufelja-Yacoubi, Data Scientist, BlockChain Developer; IBM Academy of Technology Member IBM Cloud and Cognitive Software
Kyuhwa Lee, Senior Data Scientist, IBM Cloud and Cognitive Software
Special thanks to Erika Agostinelli, Data Scientist Lead, who helped us over the development of the project, and Gianmaria Leo who provided insightful knowledge on the data understanding and decision optimization follow up.