
Motivation
One of the first measures taken against the spread of Coronavirus has been about implementing international travel restrictions. Various authorities have been imposing travel restrictions and changing them based on the actual status of case numbers. These acute changes in travel restrictions have disrupted the aviation industry like never before. Moreover, tracking the travel restrictions for each country is time-consuming. Fortunately, the Humanitarian Data Exchange website provides a consolidated dataset that shows current travel restrictions. Natural language processing (NLP) can be used to extract the travel restriction information from this dataset.
Data Used
The dataset “COVID-19 restrictions by country.csv” provided by Humanitarian Data Exchange shows current travel restrictions. Information is collected from various sources: IATA, media, national sources, WFP internal, or any other. The dataset is licensed under the Creative Commons Attribution International License Attribution 3.0 IGO. Special thanks to Humanitarian Data Exchange for providing access to the data.
Methodology
The main techniques used in extracting the country-specific travel restriction information are Part-of-speech (POS) tagging and Named-entity recognition (NER). Spacy, an open-source software library for NLP, was used to carry out the above-mentioned techniques. Since the text also contains other restriction information, sentence tokenisation was used to parse each sentence and extract the foreign country restriction information. The task was divided into three main parts:
- Preprocessing the text
- Determination of the level of restriction
- Extraction of foreign country names mentioned in the sentence
It is to be noted that not all the restrictions were extracted. Clear travel restrictions were extracted for text with simple sentence structure.
Preprocessing the text:
As the data contains text from various sources, preprocessing the text was a challenging task. Some of the steps carried out in cleaning the text include expansion of abbreviations, removing hyperlinks, white spaces, phone numbers, text within brackets. Then sentence tokenisation was carried out to split the text into individual sentences.
Determination of the level of restriction:
Only simple sentences where the meaning of the restriction is direct were considered. For example:
![]()
Exploratory data analysis was carried out to identify commonly used verbs and noun chunks in the text and labelled them into one of the two categories: positive, negative. Spacy’s inbuilt part-of-speech (POS) tagging and dependency parser were used to identify the verbs and nouns in the sentence and also to determine the subject and object of the sentence. If one of the positive verbs was present in the sentence and there was no negation in the sentence, then the sentence was marked as “open” to the mentioned countries. Similarly, if the sentence had a negative verb and there was no negation in the sentence then it was marked as “closed” to the mentioned countries. The same procedure was carried out for nouns and noun chunks as well. Rules were written manually to determine the level of restriction based on the verbs and nouns present.
The image below shows the results of POS tagging and dependency parser as a graph where the restriction level was marked as “closed” due to the presence of the verb “suspended”:
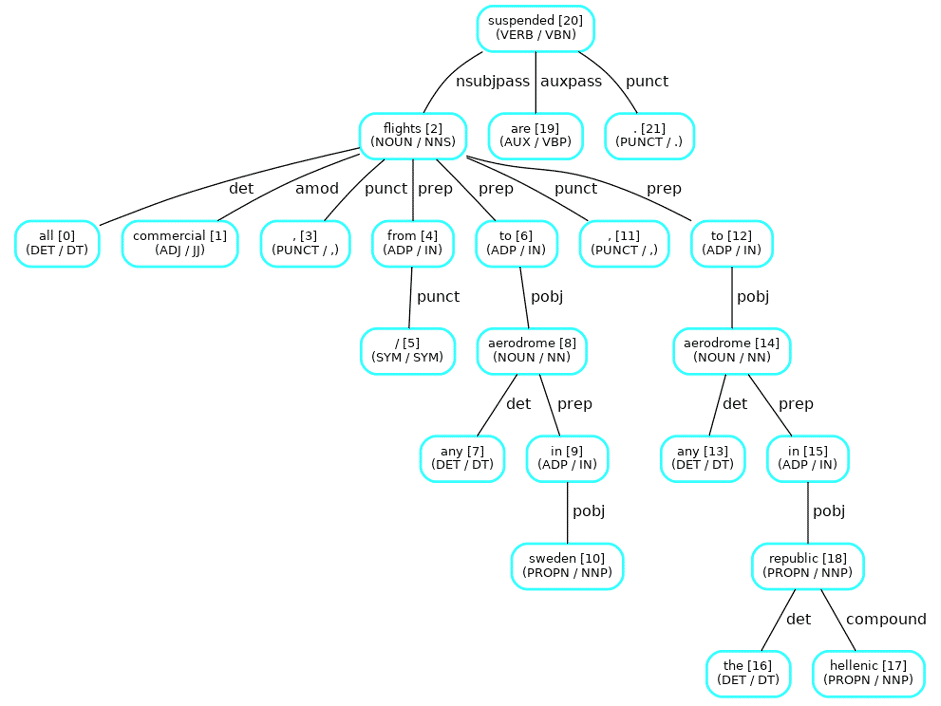
The image below shows the results of POS tagging and dependency parser as a graph where the restriction level was marked as “open” due to the presence of the verb “permitted”:
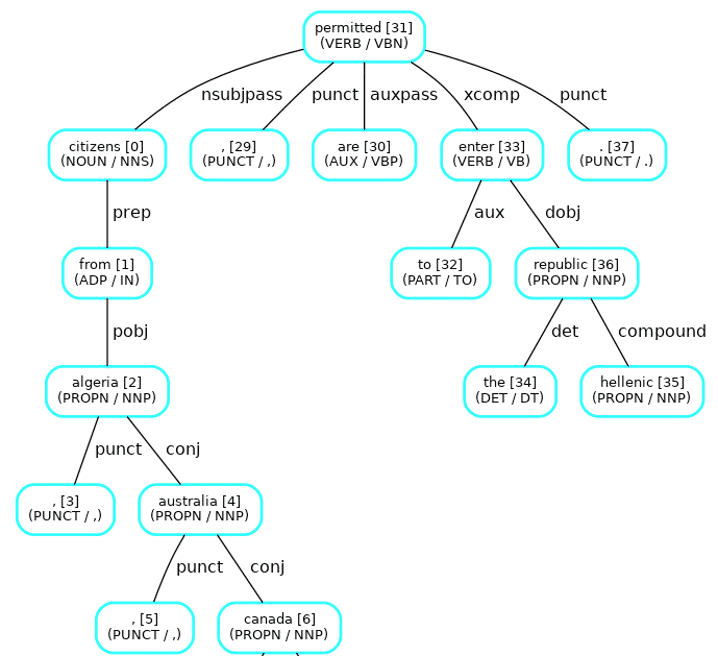
If a sentence has both positive and negative verbs/nouns then the sentence was marked as “restricted access” as the intent of restriction could not be extracted directly.
Extraction of foreign country names:
Spacy’s Named Entity Recognizer (NER) was used to identify country names mentioned in the text. It was identified that different aliases of a country name were used in the text. Some countries mention the United Kingdom as the UK, whereas some countries mention it as Great Britain. So, a list of country aliases was collected in a file and the NER was extended using Entity Ruler to identify those country names. Mention of restrictions for a group of countries such as EU, non-EU were also added to the Entity Ruler and the countries associated with these mentions were then mapped to the respective countries. Once the foreign country names were extracted from the sentences the corresponding restriction information associated with that sentence was mapped to these foreign countries.
The below image shows the country names identified by Spacy’s default NER (tagged as GPE):

The below image shows the same result as above after extending Spacy’s NER with custom patterns of country aliases:

For some countries, the entry is closed for all incoming passengers. So, the commonly used noun chunks such as “all passengers”, “all flights”, “all airports” were identified, and the restriction was mapped to all countries.
The analysis was extended to multiple weeks and the results were displayed on a world map in a dashboard.
A screenshot of the dashboard is shown below:
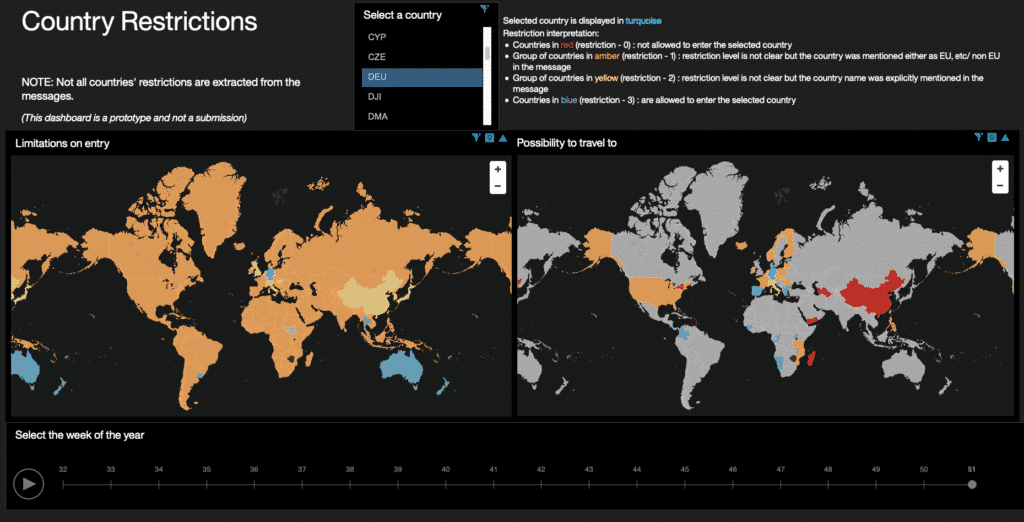
Key Takeaways
Rule-based extraction works for simple sentences with limited verbs. As the complexity of sentences increases, more rules have to be added to extract the restriction level and it becomes difficult to maintain the code. So a better approach would be to label the sentences and build a supervised learner
- Extending Spacy’s NER with custom country aliases does help in identifying most of the country names mentioned in the text
- Though most countries have severe restrictions in place, travel for medical and humanitarian purposes are allowed
Disclaimer:
This information can be used for educational and research use. The authors do not recommend generalizing the results and draw conclusions for decision-making on these sources alone.
To try out the analysis, check out the code available on GitHub.
Author:
Shri Nishanth Rajendran is AI Developer with Rolls-Royce R² Data Labs team
Special thanks to Klaus Paul, Mehrnoosh Vahdat and Maria Ivanciu who helped in this work.
We are a team of data scientists from IBM’s Data Science & AI Elite Team, IBM’s Cloud Pak Acceleration Team, and Rolls-Royce’s R² Data Labs working on Regional Risk-Pulse Index: forecasting and simulation within Emergent Alliance. Have a look at our challenge statement!