
Ana is a Data Scientist who is working on a challenge in Emergent Alliance and regularly searching for Covid-19 related datasets. She came across the work of Emergent Risk-Pulse Index challenge during a Town Hall event and recognized multiple points of relevance in terms of data and analysis to her current work. What if she could access a prepared Covid-19 data catalogue easily to explore and make use of the data in her project, and even add new datasets to the catalogue and share with others?
To support Ana and all data scientists in Emergent Alliance and to enhance collaboration within projects, we built a data repository for the Risk-Pulse Index project using Watson Knowledge Catalogue (WKC). This includes a categorized metadata repository that allows searching the assets, access, and reuse them via REST APIs or directly in an analytics project in IBM Cloud Pak for Data. Also, one can explore related assets assigned to metadata and their relationships.
Searching assets
When publishing data and assets (including models and notebooks) in WKC, we can assign tags and business terms that would allow finding related assets. Business term is the definition of key business information that is used in day-to-day business operations and analysis. They can be organized in hierarchies using type relationships as well as in high-level categories. In the current repository, we have created five data catalogues representing the categories of our assets: Health, Economy, Stringency, Mobility/Media, and Geospatial where currently over 60 data assets are published. As an example, some of the data assets in the Stringency category are assigned with ‘Stringency Index’ business term shown below.
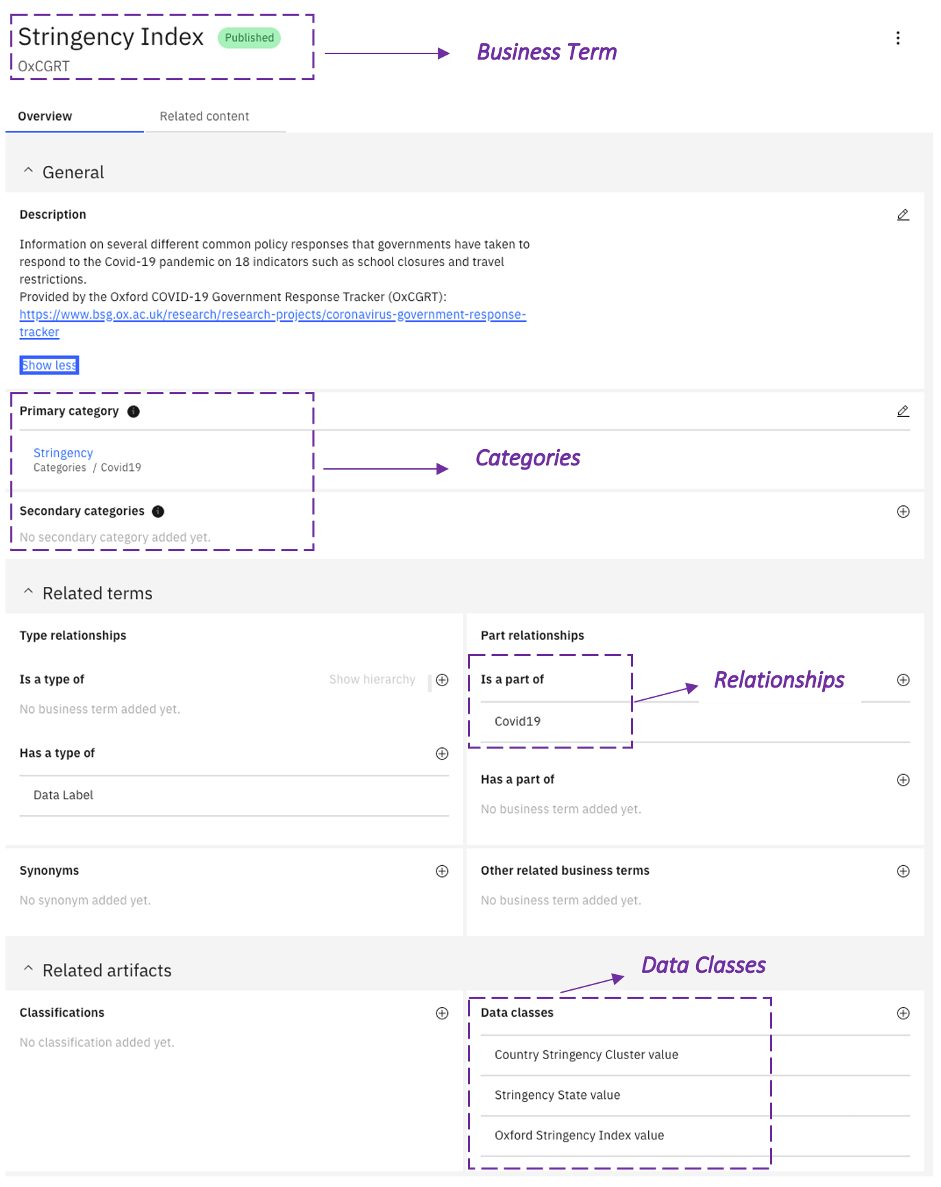
The figure above shows that ‘Stringency Index’ is a part (relationship) of ‘Covid19’ business term and belongs to the ‘Stringency’ category.
Similarly, we can assign Data Classes to the columns of a data set. Data classes describe the type of data contained in data assets, such as data fields or table columns, for example, city, account number, or credit card number. For example, ‘Oxford Stringency Index value’ is a data class related to ‘Stringency Index’.
We can also use matching methods to specify how to identify data class assignments automatically when profiling dataset columns. Data classes are necessary to mask data with policies.
Exploring content
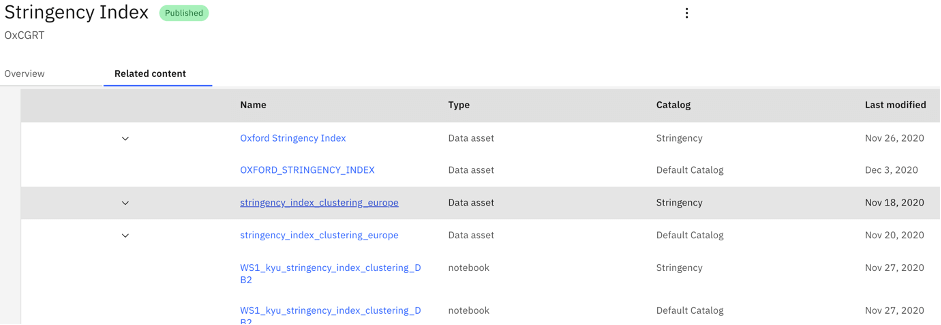
Assigning business terms in the right way allows us to explore the related content. The table below shows a view on the asset type, name of the catalogue, and the last modified date.
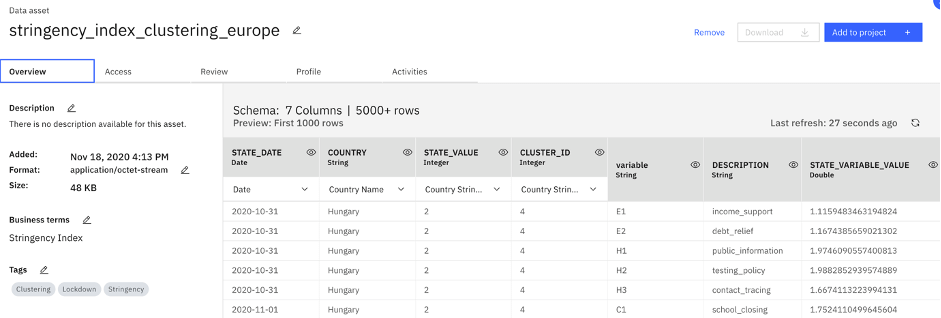
Profiling data
After finding the related content, we can then view columns of a dataset and get general statistics via the ‘Profile’ feature. The profile of a data asset includes generated metadata and statistics about the textual content of the data. Thanks to this feature, we get information on data classes and decide whether a dataset is needed, then proceed with ‘Add to project’ in Cloud Pak for Data and use the dataset easily for further analysis.
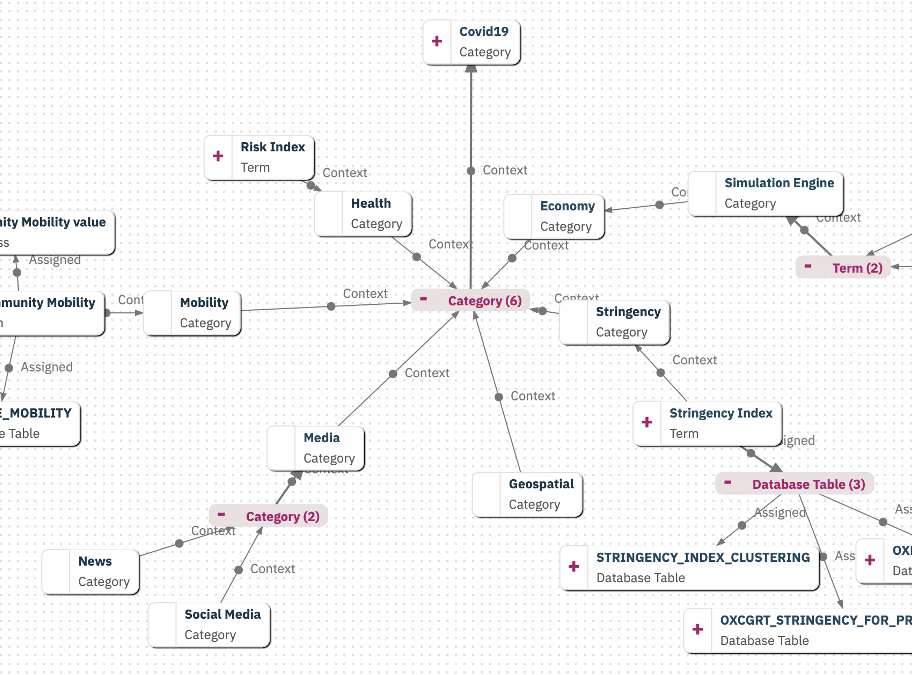
Exploring relationships
To view the relationships between metadata and assets and to better understand how data is connected, we created a knowledge graph. In the interactive graph, we can expand nodes and display relationships in a category of interest. As shown in the image below, we created six sub-categories under “Covid19“ with each a set of business terms and datasets is associated.
Tracking data repository
Through a collection of Watson Data REST APIs associated with WKC, we created a script that is scheduled as a daily job to monitor and query data assets already published in WKC. This job enables to manage catalogues efficiently and detect data assets that are not yet categorized. A word cloud of metadata captured from catalogues is shown below.

Main Takeaway
We used part of WKC capabilities to build a data asset repository of the use cases in the Emergent Risk-Pulse Index project. We showed how to get benefit from assigning metadata to assets and explore content and relationships through a knowledge graph. This work can be extended to build a data and asset ecosystem in Emergent Alliance that relies on standardized metadata and facilitates collaboration within data science teams. Future work can address automated metadata generation, data masking, and monitoring data quality.
Author
Mehrnoosh Vahdat is a Data Scientist with IBM Data Science & AI Elite team where she specializes in Data Science, Analytics platforms, and Machine Learning solutions.
Special thanks to Klaus Paul, Sarah Boufelja, Anthony Ayanwale, Shri Nishanth Rajendran, Álvaro Corrales Cano, Kareem Amin, Emma Tucker, and Alex Lavrov for their valuable contributions and support in building the data repository.
We are a team of data scientists from IBM’s Data Science & AI Elite Team, IBM’s Cloud Pak Acceleration Team, and Rolls-Royce’s R² Data Labs working on Regional Risk-Pulse Index: forecasting and simulation within Emergent Alliance. Have a look at our challenge statement!